11. Algorithm: What are the Dijkstra and Prim algorithms, and how are they implemented? How does the Fibonacci heap relate to them? Use C# . Question, Explanation, Solution. At toptal-com .
By: Chrysanthus Date Published: 3 Feb 2026
Prim's algorithm is an algorithm that finds the Minimum Spanning Tree (MST) in a connected and undirected graph. The Minimum Spanning Tree (MST) is the collection of edges required to connect all vertices in an undirected graph, with the minimum total edge weight. An edge weight is the value of an edge. Different edges can have different values.
If the edges represent roads that connect different geographical locations represented by the vertices, then the values represent the different lengths of the roads.
This is a teaching document, so for an actual interview, summarize all what is given in this document.
The rest of this article is presented according to the following table of contents:
11.1) Explanation of Dijkstra's Algorithm from Definition
11.1.1) Use of Minimum Heap with Dijkstra's Algorithm
11.1.2) Use of Fibonacci Heap with Dijkstra's Algorithm
11.2) Explanation of Prim's Algorithm from Definition
11.2.1) Use of Minimum Heap with Prim's Algorithm
11.2.2) Use of Fibonacci Heap with Prim's Algorithm
11.3) Conclusion
11.1) Explanation of Dijkstra's Algorithm from Definition
In this section, Dijkstra's Algorithm is illustrated first, before the algorithm is given as a Series of Steps. After that the code is given based on the illustration (manual-run-through).Manual-Run-Through of Dijkstra's Algorithm
Consider the following network graph:
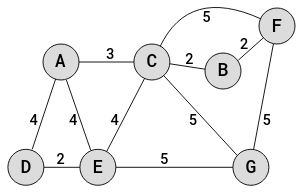
The vertices are geographical locations that are identified by letters of the alphabet. The edges are roads that link the locations (vertices). The lengths of the roads, are indicated by the edges.
The aim of Dijkstra's Algorithm here, is to find the shortest path from the single source, D to each of the other vertices, E, A, C, etc.
The first step is to set the distance from D to D itself, as 0; then set the distance to each of the other vertices from D, as infinity, as it assumes the algorithm is not yet aware of their presence. Infinity is an unimaginably large number. The following image shows this:
The aim of Dijkstra's Algorithm here, is to find the shortest path from the single source, D to each of the other vertices, E, A, C, etc.
The first step is to set the distance from D to D itself, as 0; then set the distance to each of the other vertices from D, as infinity, as it assumes the algorithm is not yet aware of their presence. Infinity is an unimaginably large number. The following image shows this:
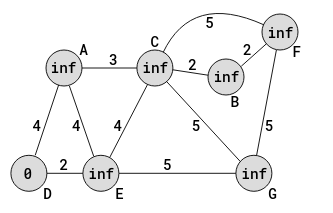
So, the distance from D to D is 0. The distance from D to E is infinity; the distance from D to A is infinity; the distance from D to C is infinity; the distance from D to G is infinity; and so on.
The next step is to identify all the neighbors of D, and their distances from this same source vertex, D. The following diagram shows this:
The next step is to identify all the neighbors of D, and their distances from this same source vertex, D. The following diagram shows this:
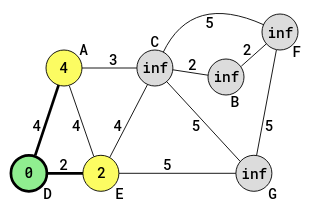
The distance from D to D is indicated in the circle of D. The shortest path-weight from D to D is 0. The distance from D to E is indicated in the circle of E. The distance from D to A is indicated in the circle of A. The rest of the distances from D remain at infinity.
The neighbors identified for D, are E and A. The E and A vertices are now unvisited vertices. Though they are known vertices, they are not yet visited. The determination of their distances are obtain from the lengths of the edges (given).
The shortest of all the unvisited vertices now has to be determined. In this case it is 2, from D to E. If more than one edge have the same distance, then any is chosen. At this point D is marked as visited. The algorithm will then go to E, which is at the shortest distance of D's unvisited neighbors. The following diagram shows what happens next:
The neighbors identified for D, are E and A. The E and A vertices are now unvisited vertices. Though they are known vertices, they are not yet visited. The determination of their distances are obtain from the lengths of the edges (given).
The shortest of all the unvisited vertices now has to be determined. In this case it is 2, from D to E. If more than one edge have the same distance, then any is chosen. At this point D is marked as visited. The algorithm will then go to E, which is at the shortest distance of D's unvisited neighbors. The following diagram shows what happens next:
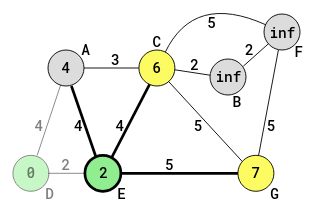
D was the previous current vertex. E is now the current vertex. At the current vertex, the algorithm identifies all the neighbors of the current vertex. It also determines the distances of all such neighbors.
For G the sum distance (path-weight) from D is 2 + 5 = 7. For C it is 2 + 4 = 6. For A it is 2 + 4 = 6 (going through E this time). This 6 is not marked in the circle of A.
The vertices G, C and A are now marked as unvisited (not yet visited). Note that A was marked from D as unvisited, and is now marked from E as also unvisited.
The reason why vertex C is not given the value 6, for path-weight D-E-C, is because the path-weight from D to A is already determined as 4, which is less than 6. The aim of the algorithm is to find the shortest path from D to any vertex, and not to find the path through any inner vertex to a next vertex.
It is possible to have a vertex marked from a previous current vertex as unvisited, which is not part of the currently marked unvisited neighbors. Above, the commonality is coincidence, and there are many such coincidences in graph networks. The fact that the algorithm moved to E does not mean that A became visited. A is still unvisited at this point. Even E is still unvisited, though it will soon become visited. D is the only vertex visited at this point.
At this point, all the unvisited vertices from D, excluding the current vertex, E have to be taken into consideration. This consists of the unvisited vertices of E and the unvisited vertices of D. A has been marked as unvisited twice: from D and from E.
Note that though D is a neighbor to E, it is not marked as unvisited. In fact, it is not even accessed, this time, by the algorithm, because it was already marked as visited. Once a vertex is marked as visited, it cannot be marked as unvisited, and the algorithm cannot visit that vertex anymore.
The aim of the algorithm is to find the shortest path from D to each vertex, and not to find the path through any inner vertex to a next vertex. At this point, the sum distances (path-weight) from D to all the unvisited vertices (except the current vertex E) are assessed to know the one that is the shortest. The unvisited vertices are G, C, and A. The vertex A is unvisited from E as well as it is unvisited from D. Here, there are two immediate origins (D and E) for the unvisited vertices. In other cases there may be more.
A above has the immediate origins of D and E. It is possible for such unvisited vertex to be independent from the other visited vertices G and C, in the sense that A would have an immediate origin of D but G and C would have an immediate origin of E, without A having both origins. However, above A has both D and E as immediate origins.
The shortest sum distance (path-weight) from vertex D, of all these unvisited vertices (of the different sets obtained), is 4, and it is from D to A.
At this point, all the possible unvisited vertices have been assessed successfully. The algorithm will next go to A (shortest unvisited vertex from D), to make A the new current vertex. Before that, E is marked as visited. The algorithm will no longer visit E or any other visited vertex. The shortest path-weight from D to E is 2. At this point, the shortest path-weight of D and E have been obtained. Then A becomes the current vertex. The following diagram shows what happens next:
For G the sum distance (path-weight) from D is 2 + 5 = 7. For C it is 2 + 4 = 6. For A it is 2 + 4 = 6 (going through E this time). This 6 is not marked in the circle of A.
The vertices G, C and A are now marked as unvisited (not yet visited). Note that A was marked from D as unvisited, and is now marked from E as also unvisited.
The reason why vertex C is not given the value 6, for path-weight D-E-C, is because the path-weight from D to A is already determined as 4, which is less than 6. The aim of the algorithm is to find the shortest path from D to any vertex, and not to find the path through any inner vertex to a next vertex.
It is possible to have a vertex marked from a previous current vertex as unvisited, which is not part of the currently marked unvisited neighbors. Above, the commonality is coincidence, and there are many such coincidences in graph networks. The fact that the algorithm moved to E does not mean that A became visited. A is still unvisited at this point. Even E is still unvisited, though it will soon become visited. D is the only vertex visited at this point.
At this point, all the unvisited vertices from D, excluding the current vertex, E have to be taken into consideration. This consists of the unvisited vertices of E and the unvisited vertices of D. A has been marked as unvisited twice: from D and from E.
Note that though D is a neighbor to E, it is not marked as unvisited. In fact, it is not even accessed, this time, by the algorithm, because it was already marked as visited. Once a vertex is marked as visited, it cannot be marked as unvisited, and the algorithm cannot visit that vertex anymore.
The aim of the algorithm is to find the shortest path from D to each vertex, and not to find the path through any inner vertex to a next vertex. At this point, the sum distances (path-weight) from D to all the unvisited vertices (except the current vertex E) are assessed to know the one that is the shortest. The unvisited vertices are G, C, and A. The vertex A is unvisited from E as well as it is unvisited from D. Here, there are two immediate origins (D and E) for the unvisited vertices. In other cases there may be more.
A above has the immediate origins of D and E. It is possible for such unvisited vertex to be independent from the other visited vertices G and C, in the sense that A would have an immediate origin of D but G and C would have an immediate origin of E, without A having both origins. However, above A has both D and E as immediate origins.
The shortest sum distance (path-weight) from vertex D, of all these unvisited vertices (of the different sets obtained), is 4, and it is from D to A.
At this point, all the possible unvisited vertices have been assessed successfully. The algorithm will next go to A (shortest unvisited vertex from D), to make A the new current vertex. Before that, E is marked as visited. The algorithm will no longer visit E or any other visited vertex. The shortest path-weight from D to E is 2. At this point, the shortest path-weight of D and E have been obtained. Then A becomes the current vertex. The following diagram shows what happens next:
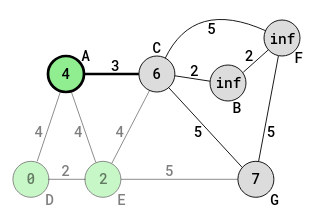
A is now the current vertex. All the neighbors of A have to be addressed, excluding the visited neighbors (neighbors marked visited). The only neighbor to address is C, since D and E have been visited. The vertex C is identified.
The distance from D to C through A, is 4 + 3 = 7. However, through the visited vertex, E the distance from D to C is 6, which is less than 7. So, the 7 obtained through A is not written in the circle of C. The shortest distance from D to C, for the different paths, remains at 6 (that was worked out when E was the current vertex).
At this point in the algorithm, there is only one unvisited vertex, so far as D is concerned. That is, whatever paths are obtained from D in the graph network, only one unvisited vertex exists, at this point in the algorithm.
The aim of the algorithm is to find the shortest path from D to each vertex, and not to find the path through any inner vertex to a next vertex. At this point, the sum distances (path-weights) from D to all the unvisited vertices, of which there is only one (now), are assessed to know the one that is the shortest (the only one is the shortest). The unvisited only vertex for now is C. The vertex C is unvisited from E (and also from A). Here, there are two immediate origins (A and E) of the unvisited vertex. In other cases there may be more. The shortest path to C is not through A, because D-A-C is longer than D-E-C. It is D-E-C.
The shortest sum distance (path-weight) from vertex D, of this unvisited vertex(of the different immediate origins), is 6 = 2 + 4 of D-E-C.
At this point, all the possible unvisited vertices for D (only one) have been assessed successfully. The algorithm will next go to C, to make C the new current vertex. Before that, A is marked as visited. The algorithm will no longer visit A or any other visited vertex. The shortest path-weight from D to A is 4. In other to obtain the shortest path of any vertex ahead, from A (from D) (which should not be confused with that of D-E-C), just add the distances to 4 of A, and no need to consider the edges of the vertices such as D that precede A. At this point, the shortest path-weight of D, E and A have been obtained. Then C becomes the current vertex. The following diagram shows what happens next:
The distance from D to C through A, is 4 + 3 = 7. However, through the visited vertex, E the distance from D to C is 6, which is less than 7. So, the 7 obtained through A is not written in the circle of C. The shortest distance from D to C, for the different paths, remains at 6 (that was worked out when E was the current vertex).
At this point in the algorithm, there is only one unvisited vertex, so far as D is concerned. That is, whatever paths are obtained from D in the graph network, only one unvisited vertex exists, at this point in the algorithm.
The aim of the algorithm is to find the shortest path from D to each vertex, and not to find the path through any inner vertex to a next vertex. At this point, the sum distances (path-weights) from D to all the unvisited vertices, of which there is only one (now), are assessed to know the one that is the shortest (the only one is the shortest). The unvisited only vertex for now is C. The vertex C is unvisited from E (and also from A). Here, there are two immediate origins (A and E) of the unvisited vertex. In other cases there may be more. The shortest path to C is not through A, because D-A-C is longer than D-E-C. It is D-E-C.
The shortest sum distance (path-weight) from vertex D, of this unvisited vertex(of the different immediate origins), is 6 = 2 + 4 of D-E-C.
At this point, all the possible unvisited vertices for D (only one) have been assessed successfully. The algorithm will next go to C, to make C the new current vertex. Before that, A is marked as visited. The algorithm will no longer visit A or any other visited vertex. The shortest path-weight from D to A is 4. In other to obtain the shortest path of any vertex ahead, from A (from D) (which should not be confused with that of D-E-C), just add the distances to 4 of A, and no need to consider the edges of the vertices such as D that precede A. At this point, the shortest path-weight of D, E and A have been obtained. Then C becomes the current vertex. The following diagram shows what happens next:
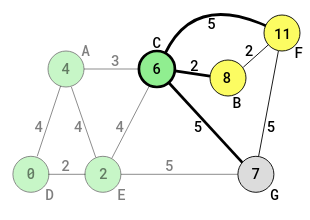
C is now the current vertex. The algorithm has to identify all its unvisited neighbors and their distances from D (the start), then the shortest path-weight chosen from among C's unvisited vertices and any other unvisited vertices (from other immediate origins), before C will be marked as visited. Neighbors marked as visited previously, are not visited again, at that point.
The neighbors identified are F, B and G.
The shortest path sum from D through C to F is 6 + 5 = 11 (no need to worry about the distance D-E again, or even D-A-C which was not accepted). So 11 replaces infinity (too large) in the circle of F. The shortest path sum from D through C to B is 6 + 2 = 8. So 8 replaces infinity (too large) in the circle of B.
Similar replacement of infinity has been taking place above (with previous vertices).
The path from D through C to G is 6 + 5 = 11. Now, 7 (=2+5) as a path-weight had already been determined for G, with the path D-E-G. Since 11 from C is more than 7, the 7 remains in the circle of G, since the overall aim is to find the shortest path to each vertex (from D). D-E-C-G (11) is not accepted.
The vertices, F and B are both the vertices from C. The vertex G is the vertex from E. All three vertices are now marked as unvisited. At this point, G has been marked as unvisited twice: once in the path D-E-G, and now in the path, D-E-C-G.
The immediate origin for F and B is C and the immediate origin for G is E (not C).
At this point, all the unvisited vertices are F, B and G, and have to be considered now.
The shortest sum distance (path-weight) from vertex D, of these unvisited vertices, is 7 = 2 + 5 for G, of D-E-G.
At this point, all the possible unvisited vertices for D have been assessed successfully. The algorithm will next go to G, to make G the new current vertex (since G has the shortest path of the three paths: D-E-C-F, D-E-C-B and D-E-G). Before that, C is marked as visited. The algorithm will no longer visit C or any other visited vertex. The shortest path-weight from D to C is 6. In other to obtain the shortest path of any vertex ahead, from C, just add the distance to 6 of C, and no need to consider the edges of the vertices such as D, E, and A, that precede C. At this point, the shortest path-weight of D, E, A and C have been obtained. Then G becomes the current vertex. The following diagram shows what happens next:
The neighbors identified are F, B and G.
The shortest path sum from D through C to F is 6 + 5 = 11 (no need to worry about the distance D-E again, or even D-A-C which was not accepted). So 11 replaces infinity (too large) in the circle of F. The shortest path sum from D through C to B is 6 + 2 = 8. So 8 replaces infinity (too large) in the circle of B.
Similar replacement of infinity has been taking place above (with previous vertices).
The path from D through C to G is 6 + 5 = 11. Now, 7 (=2+5) as a path-weight had already been determined for G, with the path D-E-G. Since 11 from C is more than 7, the 7 remains in the circle of G, since the overall aim is to find the shortest path to each vertex (from D). D-E-C-G (11) is not accepted.
The vertices, F and B are both the vertices from C. The vertex G is the vertex from E. All three vertices are now marked as unvisited. At this point, G has been marked as unvisited twice: once in the path D-E-G, and now in the path, D-E-C-G.
The immediate origin for F and B is C and the immediate origin for G is E (not C).
At this point, all the unvisited vertices are F, B and G, and have to be considered now.
The shortest sum distance (path-weight) from vertex D, of these unvisited vertices, is 7 = 2 + 5 for G, of D-E-G.
At this point, all the possible unvisited vertices for D have been assessed successfully. The algorithm will next go to G, to make G the new current vertex (since G has the shortest path of the three paths: D-E-C-F, D-E-C-B and D-E-G). Before that, C is marked as visited. The algorithm will no longer visit C or any other visited vertex. The shortest path-weight from D to C is 6. In other to obtain the shortest path of any vertex ahead, from C, just add the distance to 6 of C, and no need to consider the edges of the vertices such as D, E, and A, that precede C. At this point, the shortest path-weight of D, E, A and C have been obtained. Then G becomes the current vertex. The following diagram shows what happens next:
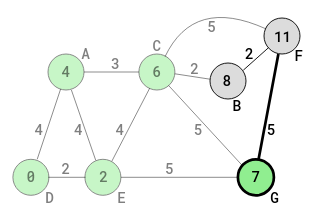
G is now the current vertex. All the neighbors of G have to be addressed, excluding the visited neighbors (neighbors marked visited). The only neighbor for G, to address is F. The vertex F is identified.
The distance from D to F through G is 7 + 5 = 12. However, through the visited vertex C (of D-E-C-F), the distance from D to F is 11, which is less than 12. So, the 11 obtained through C remains in the circle of F. F is marked as unvisited. The shortest distance from D to F, for the different paths (D-E-C-F and D-E-G-F), remains at 11.
At this point in the algorithm, there are two unvisited vertices, so far as D is concerned. They are F and B. The vertex F has been marked as unvisited twice, while B has been marked as unvisited once. Note that here, the immediate origin for B is C and the immediate origin for F is still C (not G, for shortest distance to F from D).
All the unvisited neighbors from D, no matter whether they have different immediate origins, or communality, or whether they have been marked as unvisited more than once, are now verified to see which one has the shortest distance from D. They (two of them) have to be determined through C.
The shortest path value to C is already known. It is 6. Any unvisited vertex (F or B) has to be determined from C.
The unvisited vertex with the shortest path-weight is B, with 2 from C. Shortest distance from D to B is 8 = 6 + 2, of the path D-E-C-B.
At this point, all the possible unvisited vertices for D have been assessed successfully. The algorithm will next go to B, to make B the new current vertex. Before that, G is marked as visited (C had already been marked as visited). The algorithm will no longer visit G or any other visited vertex. The shortest path-weight from D to G is 7. In other to obtain the shortest path of any vertex ahead, from G, just add the distance to 7 of G, and no need to consider the edges of the vertices such as D, E , A and C, that precede G. At this point, the shortest path-weight of D, E, A, C and G have been obtained. Then B becomes the current vertex. The following diagram shows what happens next:
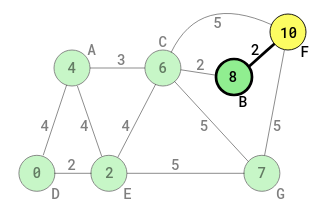
The distance from D to F through G is 7 + 5 = 12. However, through the visited vertex C (of D-E-C-F), the distance from D to F is 11, which is less than 12. So, the 11 obtained through C remains in the circle of F. F is marked as unvisited. The shortest distance from D to F, for the different paths (D-E-C-F and D-E-G-F), remains at 11.
At this point in the algorithm, there are two unvisited vertices, so far as D is concerned. They are F and B. The vertex F has been marked as unvisited twice, while B has been marked as unvisited once. Note that here, the immediate origin for B is C and the immediate origin for F is still C (not G, for shortest distance to F from D).
All the unvisited neighbors from D, no matter whether they have different immediate origins, or communality, or whether they have been marked as unvisited more than once, are now verified to see which one has the shortest distance from D. They (two of them) have to be determined through C.
The shortest path value to C is already known. It is 6. Any unvisited vertex (F or B) has to be determined from C.
The unvisited vertex with the shortest path-weight is B, with 2 from C. Shortest distance from D to B is 8 = 6 + 2, of the path D-E-C-B.
At this point, all the possible unvisited vertices for D have been assessed successfully. The algorithm will next go to B, to make B the new current vertex. Before that, G is marked as visited (C had already been marked as visited). The algorithm will no longer visit G or any other visited vertex. The shortest path-weight from D to G is 7. In other to obtain the shortest path of any vertex ahead, from G, just add the distance to 7 of G, and no need to consider the edges of the vertices such as D, E , A and C, that precede G. At this point, the shortest path-weight of D, E, A, C and G have been obtained. Then B becomes the current vertex. The following diagram shows what happens next:
B is now the current vertex. All the neighbors of B have to be addressed, excluding the visited neighbors (neighbors marked visited). The only neighbor to address is F. The vertex F is identified. There is no other vertex (for un-visiting) from any other immediate origin, other than B.
The distance from D to F through B is 8 + 2 = 10. However, through the visited vertex C, the distance from D to F is 11, which is more than 10. So, the 10 obtained through B has to replace 11, as the whole idea is to look for the shortest path-weight (total distance) from D to each vertex. F is marked as unvisited. The shortest sum distance from D to F, for the different paths so far, is 10. F has been marked as unvisited three times (two times from C and once from B).
All the unvisited neighbors from D, no matter whether they have different immediate origins, or communality, or whether they have been marked as unvisited more than once, are now verified to see which one has the shortest distance from D. There is only one unvisited vertex. The sum distance has to be determined through B. The only unvisited vertex left, for the whole algorithm, is F.
The shortest path value to B is already known, as B was already visited. It is 8. So any unvisited vertex has to be determined from B.
The unvisited vertex with the shortest path-weight is F (the only one), with 2 from B. Shortest distance from D to F is 10 = 8 + 2 of the path D-E-C-B-F.
At this point, all the possible unvisited vertices for D have been assessed successfully. The algorithm will next go to F, to make F the new current vertex. Before that, B is marked as visited. The algorithm will no longer visit B or any other visited vertex. The shortest path-weight from D to B is 8. In other to obtain the shortest path of any vertex ahead, from B, just add the distance to 8 of B, and no need to consider the edges of the vertices such as D, E, A, and C, that precede B. At this point, the shortest path-weight of D, E, A, C, G and B have been obtained. Then F becomes the current vertex.
Finalizing: F is the current vertex. The algorithm looks for any unvisited vertex from F, and finds none. The algorithm also looks for any unvisited vertex from any other immediate origin, and finds none. F is then marked as visited. The Dijkstra's Algorithm completes ! At this point, the shortest path-weight of D, E, A, C, G, B and F have been obtained.
Each vertex in the last diagram above, has its shortest path-weight (shortest distance) from D, in its circle.
- All the distances from the source vertex to its neighbors are determined. They are then marked as unvisited neighbors.
- The vertex at the shortest distance from the source vertex to any of its neighbors is determined. The source vertex is marked as visited. The neighbor with the shortest distance from the source vertex becomes the new current vertex.
- All the distances from the new current vertex to its new neighbors, except visited neighbors, are determined. They are then marked as unvisited neighbors.
- The shortest distance from the source vertex, to any unvisited vertex, off-shooting from the source vertex, plus those off-shooting from the new current vertex, is determined. The vertex for that is the next (new) current vertex. The reference for both sets of vertices, is the source vertex.
- Before going to the next current vertex, the current vertex is marked as visited. Its distance from the source vertex is noted.
The previous three steps are repeated in order, until there is no more unvisited vertex. When the shortest distance is being determined from unvisited vertices, there may be one, or two, or three, or more immediate origins from which unvisited vertices off-shoot.
- The last vertex is marked as visited.
The distance from D to F through B is 8 + 2 = 10. However, through the visited vertex C, the distance from D to F is 11, which is more than 10. So, the 10 obtained through B has to replace 11, as the whole idea is to look for the shortest path-weight (total distance) from D to each vertex. F is marked as unvisited. The shortest sum distance from D to F, for the different paths so far, is 10. F has been marked as unvisited three times (two times from C and once from B).
All the unvisited neighbors from D, no matter whether they have different immediate origins, or communality, or whether they have been marked as unvisited more than once, are now verified to see which one has the shortest distance from D. There is only one unvisited vertex. The sum distance has to be determined through B. The only unvisited vertex left, for the whole algorithm, is F.
The shortest path value to B is already known, as B was already visited. It is 8. So any unvisited vertex has to be determined from B.
The unvisited vertex with the shortest path-weight is F (the only one), with 2 from B. Shortest distance from D to F is 10 = 8 + 2 of the path D-E-C-B-F.
At this point, all the possible unvisited vertices for D have been assessed successfully. The algorithm will next go to F, to make F the new current vertex. Before that, B is marked as visited. The algorithm will no longer visit B or any other visited vertex. The shortest path-weight from D to B is 8. In other to obtain the shortest path of any vertex ahead, from B, just add the distance to 8 of B, and no need to consider the edges of the vertices such as D, E, A, and C, that precede B. At this point, the shortest path-weight of D, E, A, C, G and B have been obtained. Then F becomes the current vertex.
Finalizing: F is the current vertex. The algorithm looks for any unvisited vertex from F, and finds none. The algorithm also looks for any unvisited vertex from any other immediate origin, and finds none. F is then marked as visited. The Dijkstra's Algorithm completes ! At this point, the shortest path-weight of D, E, A, C, G, B and F have been obtained.
Each vertex in the last diagram above, has its shortest path-weight (shortest distance) from D, in its circle.
Dijkstra's Algorithm as a Series of Steps
- At the start, the source vertex is the current vertex. The shortest distance from the source vertex to the source vertex is 0. Its distance from the source vertex is noted.- All the distances from the source vertex to its neighbors are determined. They are then marked as unvisited neighbors.
- The vertex at the shortest distance from the source vertex to any of its neighbors is determined. The source vertex is marked as visited. The neighbor with the shortest distance from the source vertex becomes the new current vertex.
- All the distances from the new current vertex to its new neighbors, except visited neighbors, are determined. They are then marked as unvisited neighbors.
- The shortest distance from the source vertex, to any unvisited vertex, off-shooting from the source vertex, plus those off-shooting from the new current vertex, is determined. The vertex for that is the next (new) current vertex. The reference for both sets of vertices, is the source vertex.
- Before going to the next current vertex, the current vertex is marked as visited. Its distance from the source vertex is noted.
The previous three steps are repeated in order, until there is no more unvisited vertex. When the shortest distance is being determined from unvisited vertices, there may be one, or two, or three, or more immediate origins from which unvisited vertices off-shoot.
- The last vertex is marked as visited.
Basic Code for Dijkstra's Algorithm
The Adjacency Matrix table for the above graph is:A B C D E F G
A 3 4 4
B 2 2
C 3 2 4 5 5
D 4 2
E 4 4 2 5
F 2 5 5
G 5 5 5
The size of the matrix is 7. A, B, C, D, E, F, G are represented by the indices, 0, 1, 2, 3, 4, 5, 6. This matrix is used as input to the algorithm code given below.
There are seven main code segments in a Graph class, for the program. This does not include the main section, where the given matrix is formed and the dijkstra() function is called.
The Private Code Segment
This has the properties for the Graph class/object.
The Constructor Code Segment
This code segment (function) instantiates a graph object from the Graph class.
The addEdge() code segment
An edge here is the weight or distance from one vertex to a neighboring vertex. In the adjacency matrix, this is the value of the intersection cell of the row (index) of one of the vertices and the column (index) of the other vertex. This function (code segment) achieves that.
The addVertexData() Code Segment
This function (code segment) assigns to an index of interest, the corresponding letter (of the alphabet).
The findIndex() Code Segment
This function (code segment) takes a vertex letter as argument and returns the index.
The minDistance() Code Segment
This function (code segment) determines the shortest distance among the unvisited vertices, from the source vertex. The unvisited vertices may have the same immediate origin vertex; or may have different origin vertices; or in some cases, one unvisited vertex may have more than one immediate origin vertices; or a combination thereof.
The dijkstra() Code Segment
This function (code segment) is the core of the program. It performs the Dijkstra's algorithm. This function consists of three sub code segments.
There is a distances array whose length is the number of vertices in the graph. There is a visited array whose length is also the number of vertices in the graph. The first sub code segment here, gives the lengths of the distances and visited arrays.
When a vertex is considered visited, the value of its index is changed to true.
The second sub code segment initializes the values of the distances array.
The third code segment here, is a long for-loop, which does the rest of the Dijkstra's algorithm.
Complete Program for Basic Dijkstra's Algorithm
The complete program is as follows:
There are seven main code segments in a Graph class, for the program. This does not include the main section, where the given matrix is formed and the dijkstra() function is called.
The Private Code Segment
This has the properties for the Graph class/object.
The Constructor Code Segment
This code segment (function) instantiates a graph object from the Graph class.
The addEdge() code segment
An edge here is the weight or distance from one vertex to a neighboring vertex. In the adjacency matrix, this is the value of the intersection cell of the row (index) of one of the vertices and the column (index) of the other vertex. This function (code segment) achieves that.
The addVertexData() Code Segment
This function (code segment) assigns to an index of interest, the corresponding letter (of the alphabet).
The findIndex() Code Segment
This function (code segment) takes a vertex letter as argument and returns the index.
The minDistance() Code Segment
This function (code segment) determines the shortest distance among the unvisited vertices, from the source vertex. The unvisited vertices may have the same immediate origin vertex; or may have different origin vertices; or in some cases, one unvisited vertex may have more than one immediate origin vertices; or a combination thereof.
The dijkstra() Code Segment
This function (code segment) is the core of the program. It performs the Dijkstra's algorithm. This function consists of three sub code segments.
There is a distances array whose length is the number of vertices in the graph. There is a visited array whose length is also the number of vertices in the graph. The first sub code segment here, gives the lengths of the distances and visited arrays.
When a vertex is considered visited, the value of its index is changed to true.
The second sub code segment initializes the values of the distances array.
The third code segment here, is a long for-loop, which does the rest of the Dijkstra's algorithm.
Complete Program for Basic Dijkstra's Algorithm
The complete program is as follows:
using System;
class Program
{
class Graph {
private int[,] adjMatrix;
public string[] vertexData;
private int size;
public Graph(int size) {
this.size = size;
this.adjMatrix = new int[size, size];
this.vertexData = new string[size];
}
public void addEdge(int u, int v, int weight) {
if (u >= 0 && u < size && v >= 0 && v < size) {
adjMatrix[u, v] = weight;
adjMatrix[v, u] = weight; // For undirected graph
}
}
public void addVertexData(int vertex, string data) {
if (vertex >= 0 && vertex < size) {
vertexData[vertex] = data;
}
}
private int findIndex(string data) {
for (int i = 0; i < size; i++) {
if (vertexData[i] == data) {
return i;
}
}
return -1;
}
private int minDistance(int[] distances, bool[] visited) {
int min = int.MaxValue, minIndex = -1;
for (int v = 0; v < size; v++) {
if (!visited[v] && distances[v] <= min) {
min = distances[v];
minIndex = v;
}
}
return minIndex;
}
public int[] dijkstra(string startVertexData) {
int startVertex = findIndex(startVertexData);
int[] distances = new int[size];
bool[] visited = new bool[size];
for (int i = 0; i < size; i++) {
distances[i] = int.MaxValue;
}
distances[startVertex] = 0;
for (int i = 0; i < size; i++) {
int u = minDistance(distances, visited);
if (u == -1) break;
visited[u] = true;
for (int v = 0; v < size; v++) {
if (!visited[v] && adjMatrix[u,v] != 0 && distances[u] != int.MaxValue) {
int newDist = distances[u] + adjMatrix[u,v];
if (newDist < distances[v]) {
distances[v] = newDist;
}
}
}
}
return distances;
}
}
static void Main(string[] args)
{
Graph g = new Graph(7);
g.addVertexData(0, "A");
g.addVertexData(1, "B");
g.addVertexData(2, "C");
g.addVertexData(3, "D");
g.addVertexData(4, "E");
g.addVertexData(5, "F");
g.addVertexData(6, "G");
g.addEdge(3, 0, 4); // D - A, weight 4
g.addEdge(3, 4, 2); // D - E, weight 2
g.addEdge(0, 2, 3); // A - C, weight 3
g.addEdge(0, 4, 4); // A - E, weight 4
g.addEdge(4, 2, 4); // E - C, weight 4
g.addEdge(4, 6, 5); // E - G, weight 5
g.addEdge(2, 5, 5); // C - F, weight 5
g.addEdge(2, 1, 2); // C - B, weight 2
g.addEdge(1, 5, 2); // B - F, weight 2
g.addEdge(6, 5, 5); // G - F, weight 5
// Dijkstra's algorithm from D to all vertices
System.Console.WriteLine("Dijkstra's Algorithm starting from vertex D:\n");
int[] distances = g.dijkstra("D");
for (int i = 0; i < distances.Length; i++) {
System.Console.WriteLine("Shortest distance from D to " + g.vertexData[i] + ": " + distances[i]);
}
}
}
The output is:
Time Complexity for Basic Dijkstra's Algorithm
The time complexity for the above basic Dijkstra's Algorithm is
O(V2)
where V is the number of vertices.
O((E+V)log2V)
where V is the number of vertices and E is the number of edges.
O(E + V.log2V)
where V is the number of vertices and E is the number of edges.
Dijkstra's Algorithm starting from vertex D:Adjacency Matrix Graph Representation has been used in the code.
Shortest distance from D to A: 4
Shortest distance from D to B: 8
Shortest distance from D to C: 6
Shortest distance from D to D: 0
Shortest distance from D to E: 2
Shortest distance from D to F: 10
Shortest distance from D to G: 7
Time Complexity for Basic Dijkstra's Algorithm
The time complexity for the above basic Dijkstra's Algorithm is
O(V2)
where V is the number of vertices.
11.1.1) Use of Minimum Heap with Dijkstra's Algorithm
The array is a linear data structure. There is a non-linear data structure called minHeap. Handling elements in minHeap is generally faster that with the array. If minHeap is employed for the above code, then the time complexity will be reduced to,O((E+V)log2V)
where V is the number of vertices and E is the number of edges.
11.1.2) Use of Fibonacci Heap with Dijkstra's Algorithm
There is another non-linear data structure called Fibonacci Heap. If Fibonacci Heap is employed instead of minHeap, the time complexity will further reduce to,O(E + V.log2V)
where V is the number of vertices and E is the number of edges.
11.2) Explanation of Prim's Algorithm from Definition
In this section, Prim's Algorithm is illustrated first before the algorithm is given as a series of steps. After that the code is given based on the illustration (manual-run-through).Remember that Prim's algorithm is an algorithm that finds the Minimum Spanning Tree (MST) in a connected and undirected graph. The Minimum Spanning Tree (MST) is the collection of edges required to connect all vertices in an undirected graph, with the minimum total edge weight. An edge weight is the value of an edge. Different edges can have different values.
For Prim's algorithm to work, all the vertices in the graph must be connected.
Prim's algorithm finds the MST by first including a random vertex to the MST (while the MST is empty).
Since the starting vertex is chosen at random, it is possible to have different edges included in the MST for the same graph, but the total edge weight of the MST, will still have the same minimum value. The MST still connects all the vertices of the graph.
For simplicity, vertex A is chosen below, as the start vertex.
Manual-Run-Through of Prim's Algorithm
Consider the following network graph:
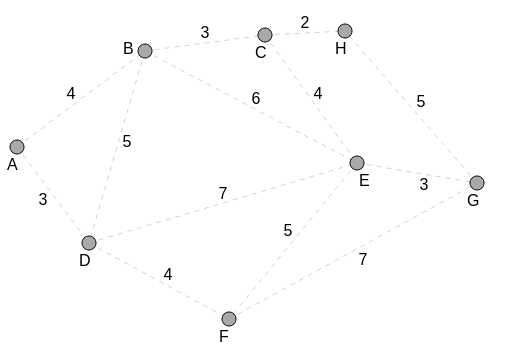
The vertices are geographical locations that are identified by letters of the alphabet. The edges are roads that link the locations (vertices). The lengths of the roads, are indicated by the edges.
The first step is to note the distance from A to A itself, as 0; then identify all the neighbors of A, and their distances from A, and note them. The following diagram shows this:
The first step is to note the distance from A to A itself, as 0; then identify all the neighbors of A, and their distances from A, and note them. The following diagram shows this:
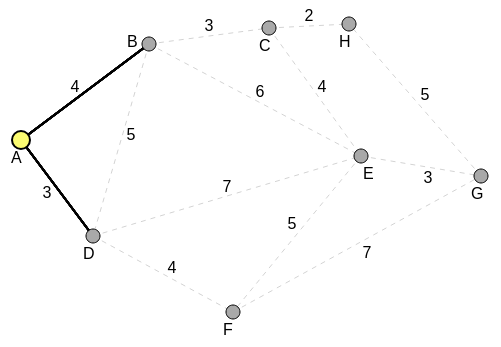
The distances A-B and A-D are compared, for the shortest distance. A-D is the shorter (shortest) distance.
A is then considered visited. The total edge weight so far, for the MST is 0. A was the previous current vertex. The new current vertex becomes D (since it is nearer to A than B). B remains an unvisited vertex which still has to be addressed. At D, all the neighbors for D and their distances are noted. The following diagram shows the new current state:
A is then considered visited. The total edge weight so far, for the MST is 0. A was the previous current vertex. The new current vertex becomes D (since it is nearer to A than B). B remains an unvisited vertex which still has to be addressed. At D, all the neighbors for D and their distances are noted. The following diagram shows the new current state:
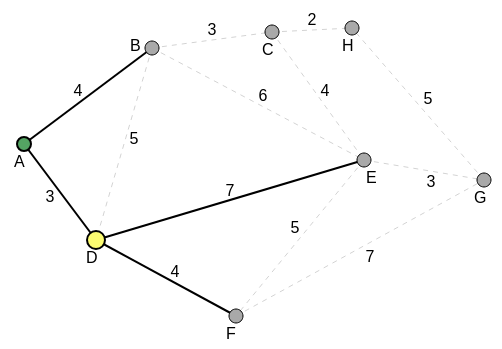
At this point all the edge weights (distances) from D to its neighbors, except that from the parent, A of D, are compared. A is already visited and will no longer be visited. This comparison is also made with that of A-B. All three edges are compared for the shortest distance. D-E is the longest distance of 7. The other two distances, D-F and A-B are the same, with value 4. For the algorithm to go forward, either of these two same shortest distances, is chosen. For this illustration (manual run through), A-B is chosen. So B becomes the next current vertex. D is considered visited (and will not be visited again). The total edge weight so far, for the MST is 3 = 0 + 3. The following diagram shows the new current state:
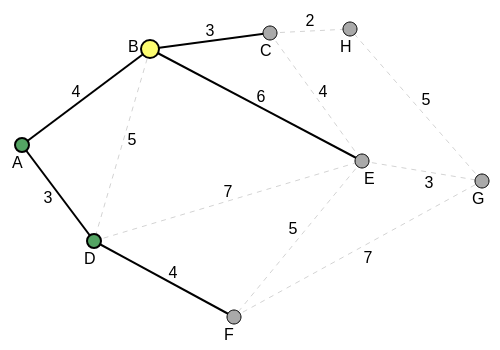
B is now the current vertex. The vertices that have been visited so far are A and D. All the edge weights (distances) from B to its neighbors, except that from the parent, A of B, are noted and compared. This comparison is also made with all the noted but non-accessed (unvisited) edges off the previously visited vertices, for the shortest edge. The edges for comparison now, are B-C with value 3, B-E with value 6, D-E with value 7, and D-F (again) with value 4. B-C with value 3 is the shortest and so C is chosen as the next current vertex. B is considered visited.
Why could E not be chosen, even if it had the shortest distance from B? - One of the rules for Prim's algorithm is that a vertex in the Minimum Spanning Tree (MST) cannot have more than one parent. The start vertex (A in this case) has 0 parent, but no other vertex in the MST should have 0 or more than one parent. Assuming that B-E and D-E had short lengths, E could still not be chosen because it would make E have two parents, B and D, which would violate the rule of single parenthood. This also prevents a cycle. A cycle is not allowed in the MST. B-E and D-E should not be among the noted un-accessed (unvisited) edges.
B is considered visited. The total edge weight so far, for the MST is 7 = 3 + 4. C becomes the current vertex. The following diagram shows the new current state:
Why could E not be chosen, even if it had the shortest distance from B? - One of the rules for Prim's algorithm is that a vertex in the Minimum Spanning Tree (MST) cannot have more than one parent. The start vertex (A in this case) has 0 parent, but no other vertex in the MST should have 0 or more than one parent. Assuming that B-E and D-E had short lengths, E could still not be chosen because it would make E have two parents, B and D, which would violate the rule of single parenthood. This also prevents a cycle. A cycle is not allowed in the MST. B-E and D-E should not be among the noted un-accessed (unvisited) edges.
B is considered visited. The total edge weight so far, for the MST is 7 = 3 + 4. C becomes the current vertex. The following diagram shows the new current state:
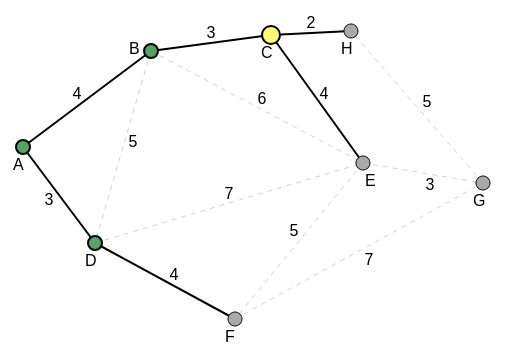
C is now the current vertex. The vertices that have been visited so far are A, D and B. All the edge weights (distances) from C to its neighbors, except that from the parent, B of C, are noted and compared. This comparison is also made with all the noted but non-accessed (unvisited) edges off the previously visited vertices; for the shortest edge. The edges for comparison now, are C-H with value 2, C-E with value 4, and D-F (again) with value 4. C-H with value 2 is the shortest and so, H is chosen as the next current vertex. C is considered visited. The total edge weight so far, for the MST is 10 = 7 + 3.
H becomes the current vertex. The following diagram shows the new current state:
H becomes the current vertex. The following diagram shows the new current state:
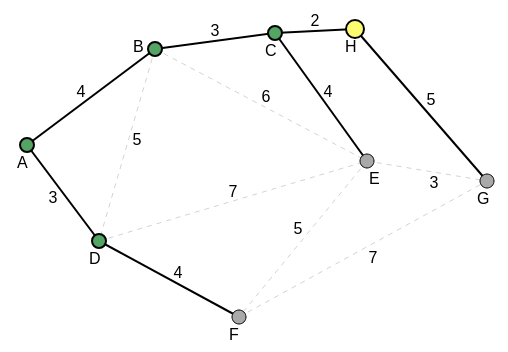
H is now the current vertex. The vertices that have been visited so far are A, D, B and C. All the edge weights (distances) from H to its neighbors, except that from the parent, C of H, are noted and compared. This comparison is also made with all the noted but non-accessed (unvisited) edges off the previously visited vertices; for the shortest edge. The edges for comparison now, are H-G with value 5, C-E (again) with value 4, and D-F (again) with value 4. H-G is the longest distance of 5. The other two distances, C-E and D-F are the same, with value 4. For the algorithm to go forward, either of these two same shortest distances, is chosen. For this illustration (manual run through), C-E is chosen. C-E with value 4 is chosen as the shortest edge of interest now. And so, E is chosen as the next current vertex. H is considered visited. The total edge weight so far, for the MST is 12 = 10 + 2.
E becomes the current vertex, and not H. The new current vertex does not necessarily have to be an offshoot of the previous current vertex. The following diagram shows the new current state:
E becomes the current vertex, and not H. The new current vertex does not necessarily have to be an offshoot of the previous current vertex. The following diagram shows the new current state:
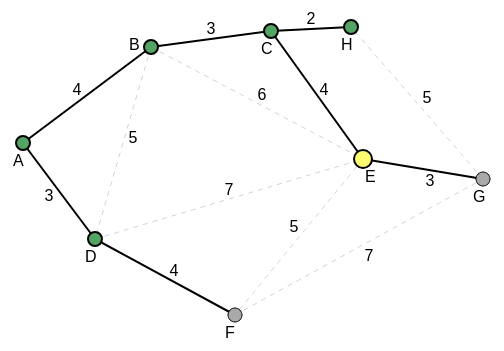
E is now the current vertex. The vertices that have been visited so far are A, D, B, C and H. All the edge weights (distances) from E to its neighbors, except that from the parent, C of E, are noted and compared. This comparison is also made with all the noted but non-accessed (unvisited) edges off the previously visited vertices; for the shortest edge.
E-B or E-D cannot be considered here: If E-B is considered, that would make E have two parents, B and C, and would create a cycle. There can be no two or more parents or any cycle in MST. If E-D is considered, that would make E have two parents, D and C, and would create a cycle. There can be no two or more parents or any cycle in MST. E-B and E-D (or in reverse direction), should not be noted as unvisited edges (vertices). That is, they should not be noted as any future edges and end vertices, as the algorithm continues.
The edges for comparison now, are E-G with value 3, and D-F (again) with value 4. E-G is the shorter (shortest) distance with value 3. E-G with value 3 is chosen as the shortest edge of interest now. And so, G is chosen as the next current vertex. E is considered visited. The total edge weight so far, for the MST is 16 = 12 + 4.
G becomes the current vertex.
G is now the current vertex. The vertices that have been visited so far are A, D, B, C, H, and E. All the edge weights (distances) from G to its neighbors, except that from the parent, E of G, are noted and compared. This comparison is also made with all the noted but non-accessed (unvisited) edges off the previously visited vertices; for the shortest edge. The only neighbor for G is F. The edges to compare are G-F with value 7 and D-F (again) with value 4. The shorter (shortest) distance, D-F of value 4 is chosen. And so, F is chosen as the next current vertex. G is considered visited. The total edge weight so far, for the MST is 19 = 16 + 3.
F becomes the current vertex.
The vertices that have been visited so far are A, D, B, C, H, E and G. All the edge weights (distances) from F to its neighbors, except that from the parent, D of F, are noted and compared. This comparison is also made with all the noted but non-accessed (unvisited) edges off the previously visited vertices; for the shortest edge.
There is apparently only one edge with end vertex for comparison now. That should be F-G. It should automatically be the shortest distance (nothing to compare with). F-G with value 7 should be chosen as the shortest edge of interest now. And so, G should be chosen as the next current vertex. F is considered visited. The total edge weight so far, but completes, for the MST is 23 = 19 + 4. Should the total edge weight so far, but completes, for the MST be 26 = 19 + 7? - No.
G is supposed to be now the current vertex again. The vertices that have been visited so far are A, D, B, C, H, E, G and F. In fact, these are all the eight vertices in the graph. All the edge weights (distances) from G to its neighbors, except that from the parent, E of G, are supposed to be noted and compared again. This comparison is also supposed to be made with all the noted but non-accessed (unvisited) edges off the previously visited vertices again; for the shortest edge. But G is already visited. There is no new unvisited neighbor for G. Also, there is no noted but non-accessed (unvisited) edges off the previously visited vertices, for the MST.
There is 0 new edge with 0 new end vertex for comparison, now. G was already visited, and cannot be visited more than once. The Prim's algorithm completes with total edge weight of 23.
All the vertices that have been visited for the MST are A, D, B, C, H, E, G and F. This set and their single edge connections form the Minimum Spanning Tree. There is no gap within this MST.
- The shortest distance from the source vertex to the source vertex is 0.
- The distances of all the neighboring vertices and the vertices are noted. They are compared for the shortest distance (edge weight).
- The vertex with the shortest distance becomes the next current vertex. The source vertex is considered visited.
- The above previous two steps are repeated continuously, in order. However, the new current vertex is not necessarily an offshoot from the current vertex. It can be an offshoot from any previously visited vertex. So comparison for the shortest vertex is made among the offshoots of the current vertex plus the offshoots of the visited vertices (if the offshoots are still unvisited).
- As the repetition of the above two steps are taking place, care is made such that no vertex has more than one parent, in order to prevent cycles. Only the source vertex has 0 parent.
There are five main code segments for the program. This does not include the main section, where the given matrix is formed and the prim() function is called.
The Private Code Segment
This has the properties for the Graph class/object.
The Constructor Code Segment
This code segment (function) instantiates a graph object from the Graph class.
The addEdge() code segment
An edge here is the weight or distance from one vertex to a neighboring vertex. In the adjacency matrix, this is the value of the intersection cell of the row (index) of one of the vertices and the column (index) of the other vertex. This function (code segment) achieves that.
The addVertexData() Code Segment
This function (code segment) assigns to an index of interest, the corresponding letter (of the alphabet).
The primsAlgorithm() Code Segment
This function (code segment) is the core of the program. It performs the Prim's algorithm. This function consists of two sub code segments.
The first sub code segment gives the length for the start vertex with the following statement:
key_values[0] = 0;
This sub code segment is just one statement.
The second sub code segment here is long. It does the rest of Prim's algorithm and printing.
Complete Program for Basic Prim's Algorithm
The complete program is as follows:
E-B or E-D cannot be considered here: If E-B is considered, that would make E have two parents, B and C, and would create a cycle. There can be no two or more parents or any cycle in MST. If E-D is considered, that would make E have two parents, D and C, and would create a cycle. There can be no two or more parents or any cycle in MST. E-B and E-D (or in reverse direction), should not be noted as unvisited edges (vertices). That is, they should not be noted as any future edges and end vertices, as the algorithm continues.
The edges for comparison now, are E-G with value 3, and D-F (again) with value 4. E-G is the shorter (shortest) distance with value 3. E-G with value 3 is chosen as the shortest edge of interest now. And so, G is chosen as the next current vertex. E is considered visited. The total edge weight so far, for the MST is 16 = 12 + 4.
G becomes the current vertex.
G is now the current vertex. The vertices that have been visited so far are A, D, B, C, H, and E. All the edge weights (distances) from G to its neighbors, except that from the parent, E of G, are noted and compared. This comparison is also made with all the noted but non-accessed (unvisited) edges off the previously visited vertices; for the shortest edge. The only neighbor for G is F. The edges to compare are G-F with value 7 and D-F (again) with value 4. The shorter (shortest) distance, D-F of value 4 is chosen. And so, F is chosen as the next current vertex. G is considered visited. The total edge weight so far, for the MST is 19 = 16 + 3.
F becomes the current vertex.
The vertices that have been visited so far are A, D, B, C, H, E and G. All the edge weights (distances) from F to its neighbors, except that from the parent, D of F, are noted and compared. This comparison is also made with all the noted but non-accessed (unvisited) edges off the previously visited vertices; for the shortest edge.
There is apparently only one edge with end vertex for comparison now. That should be F-G. It should automatically be the shortest distance (nothing to compare with). F-G with value 7 should be chosen as the shortest edge of interest now. And so, G should be chosen as the next current vertex. F is considered visited. The total edge weight so far, but completes, for the MST is 23 = 19 + 4. Should the total edge weight so far, but completes, for the MST be 26 = 19 + 7? - No.
G is supposed to be now the current vertex again. The vertices that have been visited so far are A, D, B, C, H, E, G and F. In fact, these are all the eight vertices in the graph. All the edge weights (distances) from G to its neighbors, except that from the parent, E of G, are supposed to be noted and compared again. This comparison is also supposed to be made with all the noted but non-accessed (unvisited) edges off the previously visited vertices again; for the shortest edge. But G is already visited. There is no new unvisited neighbor for G. Also, there is no noted but non-accessed (unvisited) edges off the previously visited vertices, for the MST.
There is 0 new edge with 0 new end vertex for comparison, now. G was already visited, and cannot be visited more than once. The Prim's algorithm completes with total edge weight of 23.
All the vertices that have been visited for the MST are A, D, B, C, H, E, G and F. This set and their single edge connections form the Minimum Spanning Tree. There is no gap within this MST.
Prim's Algorithm in a Series of Steps
- The start vertex is chosen at random. For simplicity, the start vertex for the code below is A.- The shortest distance from the source vertex to the source vertex is 0.
- The distances of all the neighboring vertices and the vertices are noted. They are compared for the shortest distance (edge weight).
- The vertex with the shortest distance becomes the next current vertex. The source vertex is considered visited.
- The above previous two steps are repeated continuously, in order. However, the new current vertex is not necessarily an offshoot from the current vertex. It can be an offshoot from any previously visited vertex. So comparison for the shortest vertex is made among the offshoots of the current vertex plus the offshoots of the visited vertices (if the offshoots are still unvisited).
- As the repetition of the above two steps are taking place, care is made such that no vertex has more than one parent, in order to prevent cycles. Only the source vertex has 0 parent.
Basic Code for Prim's Algorithm
The Adjacency Matrix table for the above graph for Prim is:A B C D E F G HThe size of the matrix is 8. A, B, C, D, E, F, G, H are represented by the indices, 0, 1, 2, 3, 4, 5, 6, 7. This matrix is used as input to the algorithm code given below.
A 4 3
B 4 3 5 6
C 3 4 2
D 3 5 7 4
E 6 4 7 5 3
F 4 7
G 3 7 5
H 2 5 5
There are five main code segments for the program. This does not include the main section, where the given matrix is formed and the prim() function is called.
The Private Code Segment
This has the properties for the Graph class/object.
The Constructor Code Segment
This code segment (function) instantiates a graph object from the Graph class.
The addEdge() code segment
An edge here is the weight or distance from one vertex to a neighboring vertex. In the adjacency matrix, this is the value of the intersection cell of the row (index) of one of the vertices and the column (index) of the other vertex. This function (code segment) achieves that.
The addVertexData() Code Segment
This function (code segment) assigns to an index of interest, the corresponding letter (of the alphabet).
The primsAlgorithm() Code Segment
This function (code segment) is the core of the program. It performs the Prim's algorithm. This function consists of two sub code segments.
The first sub code segment gives the length for the start vertex with the following statement:
key_values[0] = 0;
This sub code segment is just one statement.
The second sub code segment here is long. It does the rest of Prim's algorithm and printing.
Complete Program for Basic Prim's Algorithm
The complete program is as follows:
using System;
using System.Linq;
class Program
{
private class Graph {
int size;
int[,] adjMatrix;
string[] vertexData;
bool[] inMST;
int[] keyValues;
int[] parents;
public Graph(int size) {
this.size = size;
this.adjMatrix = new int[size, size];
this.vertexData = new string[size];
this.inMST = new bool[size];
this.keyValues = new int[size];
this.parents = new int[size];
Array.Fill(this.keyValues, int.MaxValue);
Array.Fill(this.parents, -1);
}
public void addEdge(int u, int v, int weight) {
adjMatrix[u,v] = weight;
adjMatrix[v,u] = weight;
}
public void addVertexData(int vertex, string data) {
vertexData[vertex] = data;
}
public void primsAlgorithm() {
keyValues[0] = 0;
System.Console.WriteLine("Edge"+ " \t" + "Weight");
for (int count = 0; count < size; count++) {
int u = -1;
int min = int.MaxValue;
for (int v = 0; v < size; v++) {
if (!inMST[v] && keyValues[v] < min) {
min = keyValues[v];
u = v;
}
}
inMST[u] = true;
if (parents[u] != -1) {
System.Console.WriteLine(vertexData[parents[u]] + "-" + vertexData[u] + " \t" + adjMatrix[u, parents[u]]);
}
for (int v = 0; v < size; v++) {
if (adjMatrix[u,v] != 0 && !inMST[v] && adjMatrix[u,v] < keyValues[v]) {
parents[v] = u;
keyValues[v] = adjMatrix[u,v];
}
}
}
}
}
static void Main(string[] args)
{
Graph g = new Graph(8);
g.addVertexData(0, "A");
g.addVertexData(1, "B");
g.addVertexData(2, "C");
g.addVertexData(3, "D");
g.addVertexData(4, "E");
g.addVertexData(5, "F");
g.addVertexData(6, "G");
g.addVertexData(7, "H");
g.addEdge(0, 1, 4); // A - B
g.addEdge(0, 3, 3); // A - D
g.addEdge(1, 2, 3); // B - C
g.addEdge(1, 3, 5); // B - D
g.addEdge(1, 4, 6); // B - E
g.addEdge(2, 4, 4); // C - E
g.addEdge(2, 7, 2); // C - H
g.addEdge(3, 4, 7); // D - E
g.addEdge(3, 5, 4); // D - F
g.addEdge(4, 5, 5); // E - F
g.addEdge(4, 6, 3); // E - G
g.addEdge(5, 6, 7); // F - G
g.addEdge(6, 7, 5); // G - H
System.Console.WriteLine("Prim's Algorithm MST:");
g.primsAlgorithm();
}
}
The output is (the start vertex is A):
Prim's Algorithm MST:Adjacency Matrix Graph Representation has been used in the code.
Edge Weight
A-D 3
A-B 4
B-C 3
C-H 2
C-E 4
E-G 3
D-F 4
Time Complexity for Basic Prim's Algorithm
The time complexity for the above basic Prim's Algorithm is
O(V2)
where V is the number of vertices.
11.2.1) Use of Minimum Heap with Prim's Algorithm
The array is a linear data structure. There is a non-linear data structure called minHeap. Handling elements in minHeap is generally faster that with the array. If minHeap is employed for the above code, then the time complexity will be reduced to,O((E+V)log2V)
where V is the number of vertices and E is the number of edges.
11.2.2) Use of Fibonacci Heap with Prim's Algorithm
There is another non-linear data structure called Fibonacci Heap. If Fibonacci Heap is employed instead of minHeap, the time complexity will further reduce to,O(E + V.log2V)
where V is the number of vertices and E is the number of edges.
11.3 Conclusion
The time complexity for either of the basic algorithm isO(V2)
If minHeap is employed, the time complexity will decrease to
O((E+V)log2V)
If Fibonacci Heap is employed, the time complexity will decrease further to,
O(E + V.log2V)